About Me
Hi! I’m Raj Rawariya, a fourth-year undergraduate at NIT Goa, majoring in Electrical and Electronics Engineering with a minor in Computer Science. I’m passionate about software engineering, systems design, and machine learning, and I enjoy building products that merge intelligent automation with clean engineering.
My interests broadly lie at the intersection of distributed systems, AI applications, and developer tooling. I love working on projects that optimize performance, simplify workflows, and make technology more accessible. Recently, I’ve been exploring cloud infrastructure, container orchestration, and autonomous systems for robotics.
I enjoy software development, full-stack development, AI, robotics, and competitive programming. I have experience leading teams, developing projects, and contributing to tech communities.
Projects
Media Server
LiveJun 2025 - Aug 2025
Self-hosted media management and streaming platform with intelligent monitoring and performance optimization.
- Created download manager and adaptive streaming engine.
- Created real-time server status APIs
- Preprocessed industry-standard media server
- Optimized player for low-bandwidth conditions
- Server monitoring for space, bandwidth, uptime
- Alerts via email for anomalies
- Self-hosted complete infrastructure.
- Enhanced media delivery under low data speed(2G/3G)
- Advanced monitoring ensured uptime and detect server problems
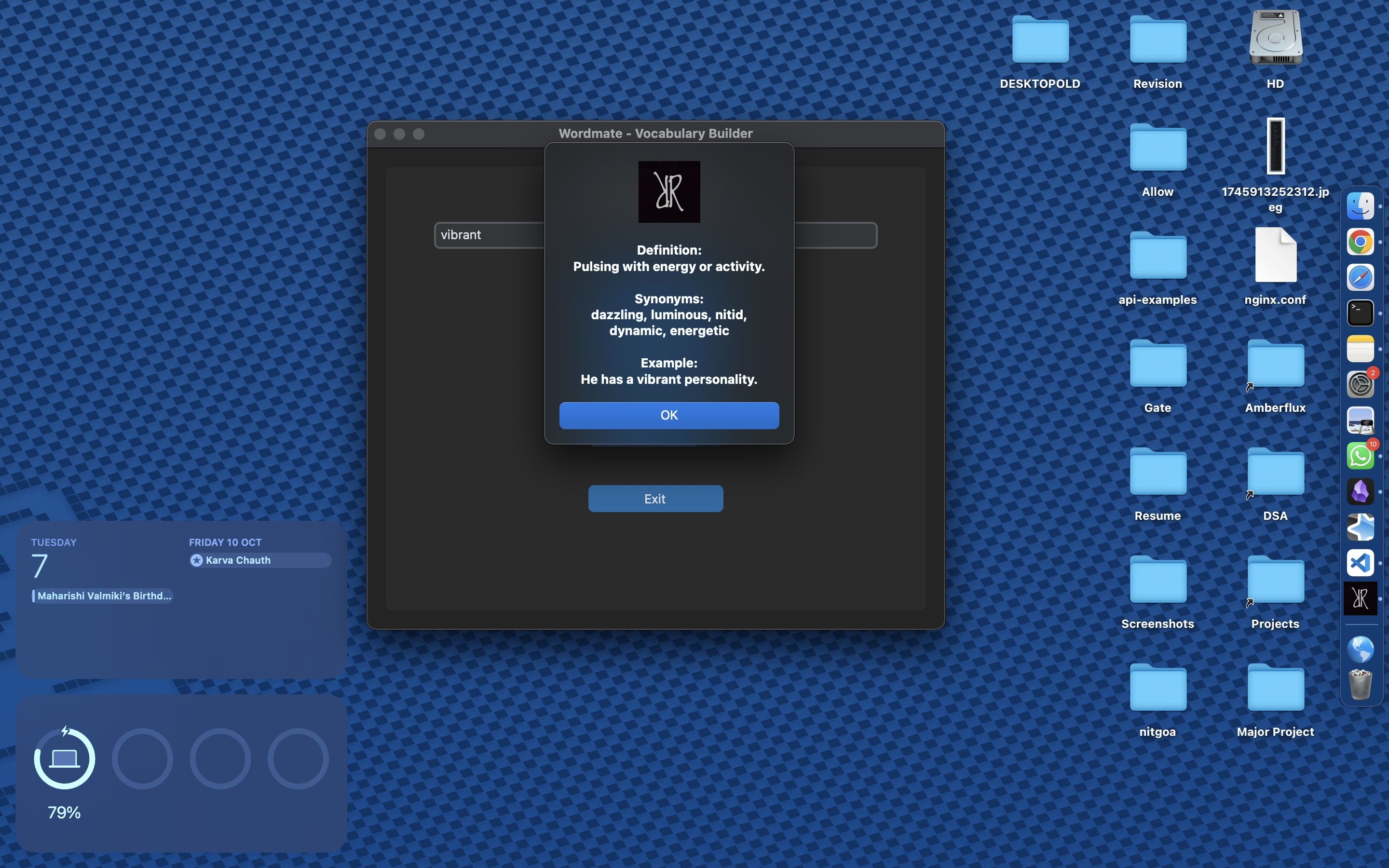
Vocab
LiveNov 2024 - Dec 2024
Vocabulary learning platform with gamified progress tracking and quizzes to enhance word retention.
- Cross platform tool available as cli, dmg and exe
- AI-powered word difficulty analysis
- Built for responsive mobile and web experience
- Improves vocabulary and saves time by faster search.
- Inculcated reading habbits
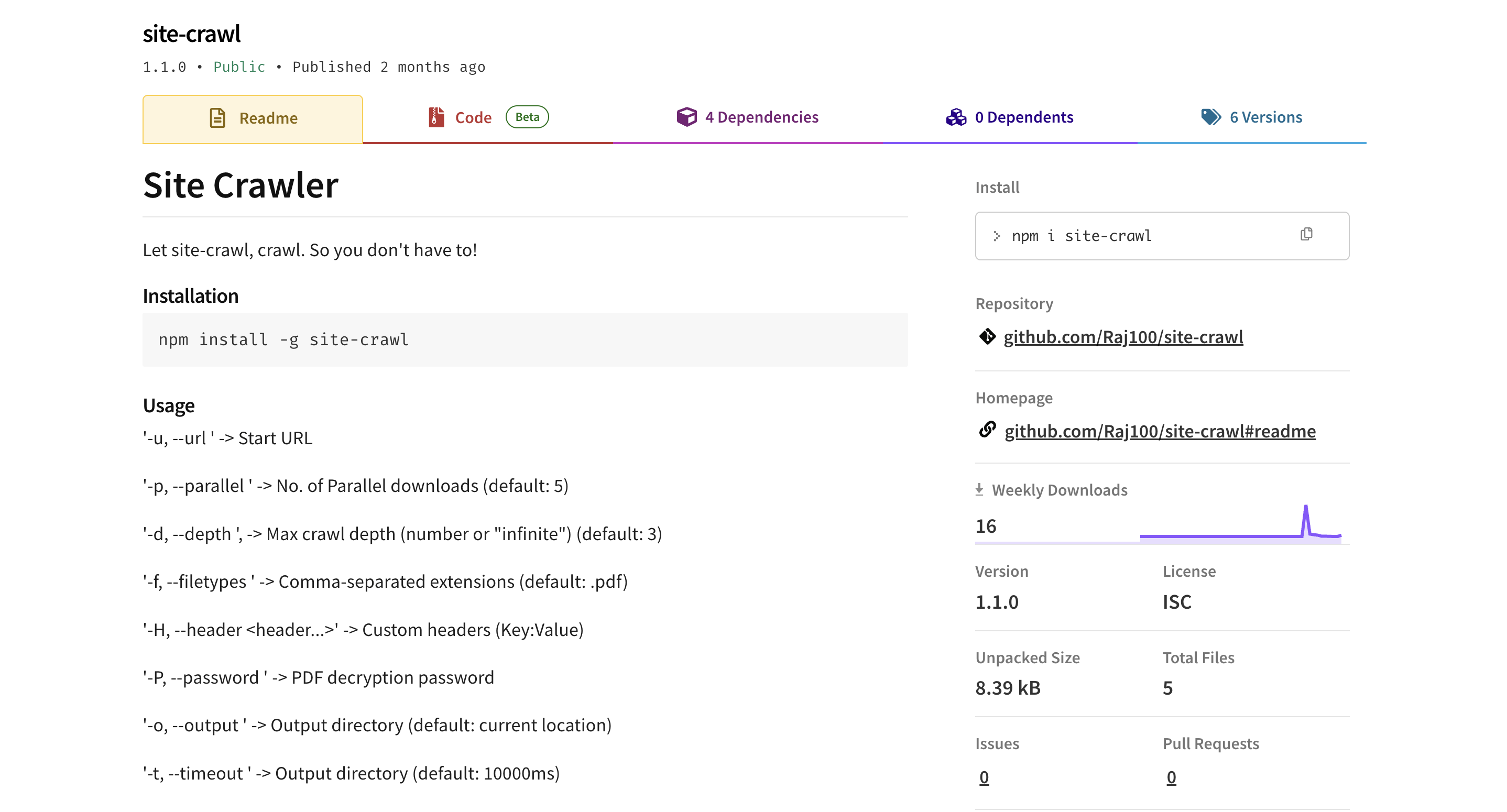
Site-Crawl CLI Tool
PublishedJune 2025
Command-line utility to crawl websites and download PDFs, images, and other assets efficiently using headless browsing.
- Let site-crawl, crawl. So you don't have to!
- Automates content scraping and file downloads
- Supports PDFs, images, and any custom file extensions
- Runs in Node.js using Puppeteer for headless automation
Contact
- Email: me@raj.ac
- GitHub: github.com/raj100
- LinkedIn: linkedin.com/in/raj-rawariya/